- Teb's Lab
- Posts
- GPT Doesn't Understand Randomness
The Workbench
I’m Tyler Elliot Bettilyon (Teb) and this is The Workbench: Our practical, hands-on edition. Our goal is to demonstrate concepts and ideas we cover in The Lab Report — our monthly deep-dive.
If you’re new to the Lab Report you can subscribe here.
If you like what you’re reading you’ll love one of our classes. Signup for an upcoming class, browse our course catalog for corporate trainings, or request a custom class consultation.
Two Quick Updates From The Lab
1) We started using a bunch of social media. If you use social media, consider following us on X/Twitter, Facebook, LinkedIn, Mastadon, YouTube, and Threads.
2) We are now an official training vendor with Salesforce. If you’re a Salesforce employee, you can be reimbursed for taking any of our open-enrollment classes!
Background: Tokenization
This post all started when a friend shared this fascinating research paper about how tokenization schemes dramatically affect how well LLMs perform arithmetic.
Tokenization is the process of turning words, parts of words, numbers, punctuation marks, and everything else fed to LLMs into unique “tokens.” These tokens, rather than words, represent the smallest unit of information processed by an LLM.
There are a variety of strategies for tokenization.
Early NLP often used whole-word tokenization, where each word gets a unique token. Word piece tokenization remains somewhat popular. This scheme gives common prefixes and suffixes — things like ”re-” “-ed” and “-ing” — unique tokens. This can help systems understand grammar and reduces token count compared to whole-word strategies.
These tokenization schemes have to take specific features of the target language into account. They only work well in languages that have clear word boundaries in their written form. They also struggle with unknown “out of vocabulary” words like slang, names, misspellings, and oddities like URLs.
Byte-pair encoding is one of the most popular techniques because it’s totally agnostic to the language or type of text being processed. It also handles “out of vocabulary” situations mostly gracefully. But it sometimes produces tokens that are linguistically irrelevant or misleading by breaking words into parts based on commonality rather than explicit grammatical features of the language.
There are also specialized tactics for numbers, although they are not yet widely adopted.
Tokenization is widely understood to be a possible source of errors, but no one has invented a great replacement for it, either. Here’s an example of GPT-4’s tokenizer, which I hope demonstrates some possible issues with tokenization (OpenAI hosts this widget online):

An example of GPT-4’s tokenizer run on the sentence “She dragged 37 men, 1005, and a Dragonite down to the riverbank. They were all drugged.”
Notice that 37 gets its own whole token, but 1005 is broken into 100 and 5. Something similar happens to Dragon-ite, river-bank, and dr-ugged.
Breaking apart a word or number means the system has to learn that those tokens combine to have a unique meaning: a “riverbank” isn’t a financial institution for waterways, for example. LLMs can learn these kinds of combos, but it is also a source of error and added complexity for the machine.
For example, I asked ChatGPT (GPT-4) about rivers, banks, riverbanks, dragons, the suffix -ite, and dragonite. It did very well. However, it did hege a little with dragonite. After appropriately identifying it as a Pokemon it dropped this nugget:
In Mineralogy: The term "dragonite" does not refer to a recognized mineral in scientific contexts. Names of minerals typically end in "-ite," but "dragonite" is not a term used in mineralogy. It's possible to encounter "dragonite" in fictional or commercial contexts unrelated to the systematic naming conventions of minerals.
And, according to the paper that kicked this all off, the tokenization scheme makes a huge difference in how the LLM performs arithmetic.
GPT’s tokenizer only has unique tokens for 3-digit-or-fewer numbers. When tokenizing larger numbers, “left to right” and “right to left” describe how to break the number into smaller tokens. For the number 1439 left to right yields 143 and 9; right to left yields 1 and 439.
The paper found that when GPT-4 adds numbers of differing lengths the accuracy depends immensely on the tokenization scheme. With a right to left (R2L) tokenizer, the accuracy was in the high 90% range. With a left to right (L2R) tokenizer, the accuracy on the same problems was 8.25%

This chart compares GPT-4’s accuracy on simple addition problems with the same number of digits vs different numbers of digits for “left to right” (L2R) and “right to left” (R2L) tokenization schemes. Source: The paper we’re writing about, https://arxiv.org/html/2402.14903v1
What’s more, they found in this condition, the error is almost always in the 4th digit. Very weird, totally awesome finding.

Chart showing that nearly all the errors come in the 4th digit. Source: that paper again https://arxiv.org/html/2402.14903v1
This all inspired me to do some impromptu research of my own regarding how GPT handles numbers. I asked ChatGPT to “generate 1000 random numbers.” Here’s what it gave me (the ellipsis is from ChatGPT, not me):
0 7 10 23 31 44 56 67 72 85 98 105 114 122 135 142 155 167 175 183 196 203 219 222 234 247 253 262 274 289 297 305 310 328 334 341 359 366 373 389 393 407 416 424 430 445 454 461 476 482 497 503 519 522 534 541 558 566 571 589 594 608 615 627 634 647 654 663 678 681 695 701 715 722 739 748 753 769 775 787 799 804 819 820 835 841 854 868 872 888 893 902 919 927 935 949 954 960 973 980 997 999 1006 1019 1027 1044 1056 1068 1081 1089 1103 1112 1120 1137 1148 1157 1173 1176 1189 1204 1208 1219 1231 1242 1255 1257 1272 1284 1296 1310 1319 1331 1337 1344 1358 1367 1374 1378 1395 1403 1418 1423 1434 144...
Here are the numbers ChatGPT generated in the order they were generated.
Instead of 1000 random numbers, ChatGPT gave me 143 integers between 1 and 1434, in sorted order, followed by an ellipsis as if to say, “I know you asked me to generate 1000 numbers, but I’m not going to.”
So — obviously — I had to dig deeper.
GPT Doesn’t Understand Randomness … and Struggles With Quantities.
The original datasets, code for producing more datasets, and the scripts I used to analyze the data can all be found here.
FYI, code snippets render better on our blog than in email.
I used OpenAI’s API to generate 60 datasets. Specifically, I asked GPT-3.5-turbo to:
"Generate n random numbers."20 times each for n=10, n=100, and n=1000. I also used a system prompt to ask the model to give its answer using only numbers separated by a space. Here’s the function that I called 60 times:
def produce_prompt_kwargs(num_of_nums):
"""
Produce a dict that fits the OpenAI API for chat completion.
The content of the user prompt changes with num_of_nums, and the seed
is randomly generated. Everything else is deterministic.
"""
user_prompt_content = f'Generate {num_of_nums} random numbers.'
seed = random.getrandbits(32) # Produce a random 32-bit integer
return {
'model': "gpt-3.5-turbo",
'messages': [
{
"role": "system", # Without this GPT added friendly but awkward to parse text to the output.
"content": "You are a number generator. In all of your responses only use numbers, with each number separated using a space."
},
{
"role": "user",
"content": user_prompt_content
}],
'temperature': 1,
'max_tokens': 4096, # Artificially large, GPT should generate many fewer if it follows the prompt.
'top_p': 1,
'frequency_penalty': 0,
'presence_penalty': 0,
'seed': seed
}
Then, I fed those dictionaries as arguments to the OpenAI API and saved the result:
def request_then_serialize(client, api_kw_args, folder_path, filename):
response = client.chat.completions.create(**api_kw_args)
json_to_save = {
'request_arguments': api_kw_args,
'system_fingerprint': response.system_fingerprint,
'id': response.id,
'model_version': response.model,
'text_response': response.choices[0].message.content,
'finish_reason': response.choices[0].finish_reason
}
with open(folder_path/filename, 'w') as f:
json.dump(json_to_save, f)
Then, I started exploring. Here are some of my favorite results:
GPT only ever returned positive integers or 0. My prompt didn’t include any details about bounds, or what kinds of numbers I might want, so I thought it was interesting that I got integers with perfect consistency.
The bounds for those integers seem influenced by the number of numbers. When asking for 10 or 100 numbers GPT returned numbers strictly between 0 - 100 inclusive.
When asking for 1000 numbers the lower bounds were usually a single digit number, but got as large as 87. The upper bounds were less predictable. The largest number GPT produced was 984,752,398. Another dataset topped off at 8,294. There was some sense of consistency, though: The most common upper bounds were 999 and 99 at four occurrences each. 100 occurred twice, as did 998.
GPT was bad at producing the correct quantity of numbers: It never correctly generated 1000 numbers, and it only generated exactly 100 numbers 3 out of 20 times. It correctly generated 10 numbers in 20 of 20 attempts.
When asked for 100 numbers, it wasn’t super far off — producing anywhere from 85 to 103 numbers in 20 tests. When asked for 1000 numbers, though, GPT was all over the place. Sometimes it returned as few as 100 numbers. Other times the API cut off GPT’s output for reaching the maximum token length I specified; that happened seven times.
In each of those seven cases, GPT returned 2048 numbers at a limit of 4096 tokens, which means it only ever returned numbers that fit in a single token (plus a space token between each number, plus the stop token).
GPT was good, but not completely reliable, in terms of output format: Once, despite my system prompt, it added some friendly text to the output. It was during a prompt for 1000 numbers, and GPT replied:
I can provide 100 random numbers:
[the numbers]
Let me know if you would like more numbers!For the record: I asked for 1000, it told me it could give me 100, but it actually gave me 116.
Five times, it added something to the final number, preventing it from parsing properly without extra work. Twice, it added an ellipsis (e.g., “4…”). Twice, it added a single period (e.g., “6.”). And once it ended its output with “93stringstream,” which gave me a nice laugh.
GPT tended towards extremely uniform distributions — much more uniform than randomly drawing from a uniform distribution. In fact, When asked for 10 numbers, GPT never repeated a number in any of the samples.
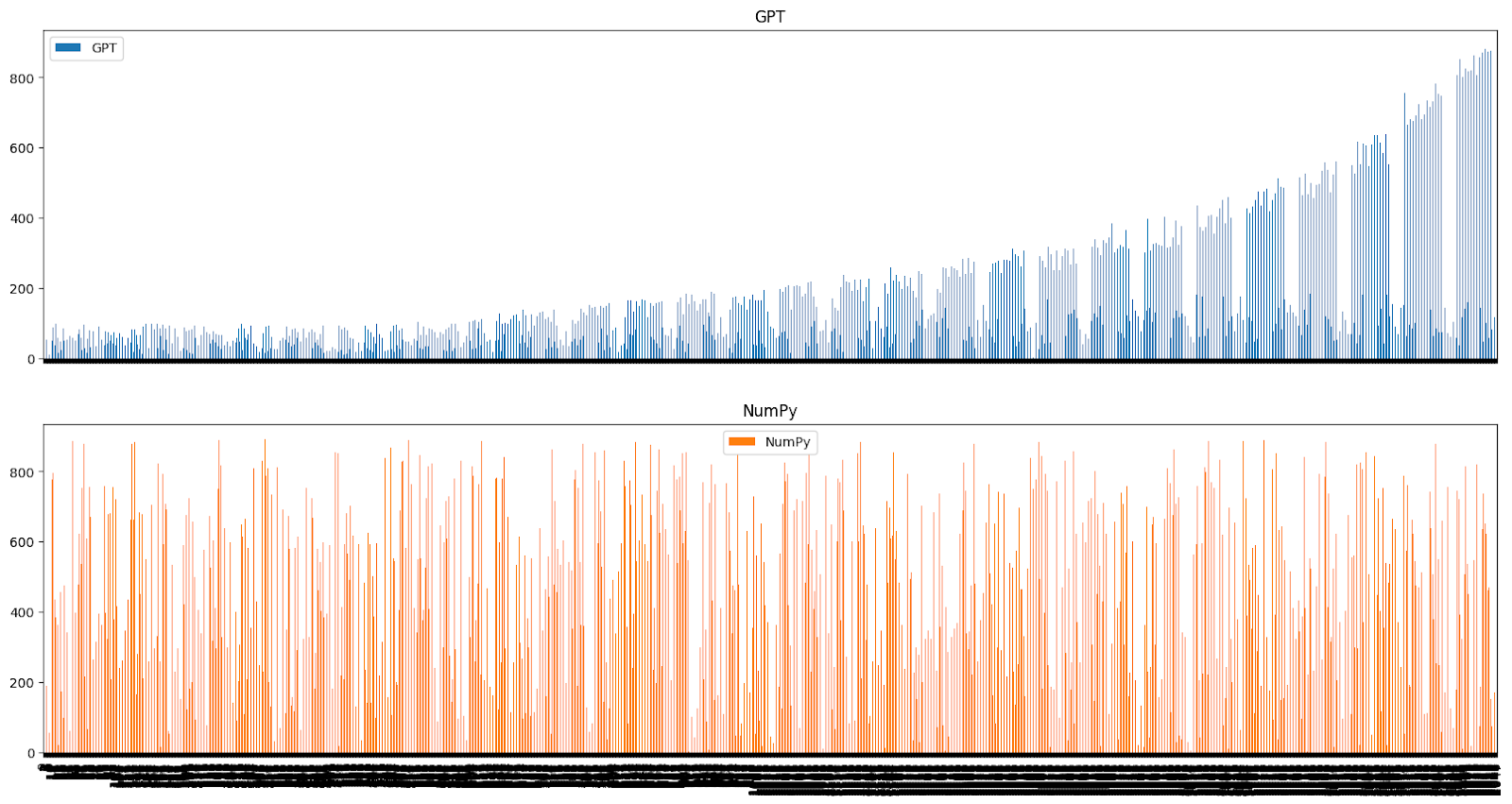
Here are some histograms demonstrating the uniformity. GPT’s output is in blue and a distribution using the same number of numbers and same range, but produced by numpy.random.randint in orange.
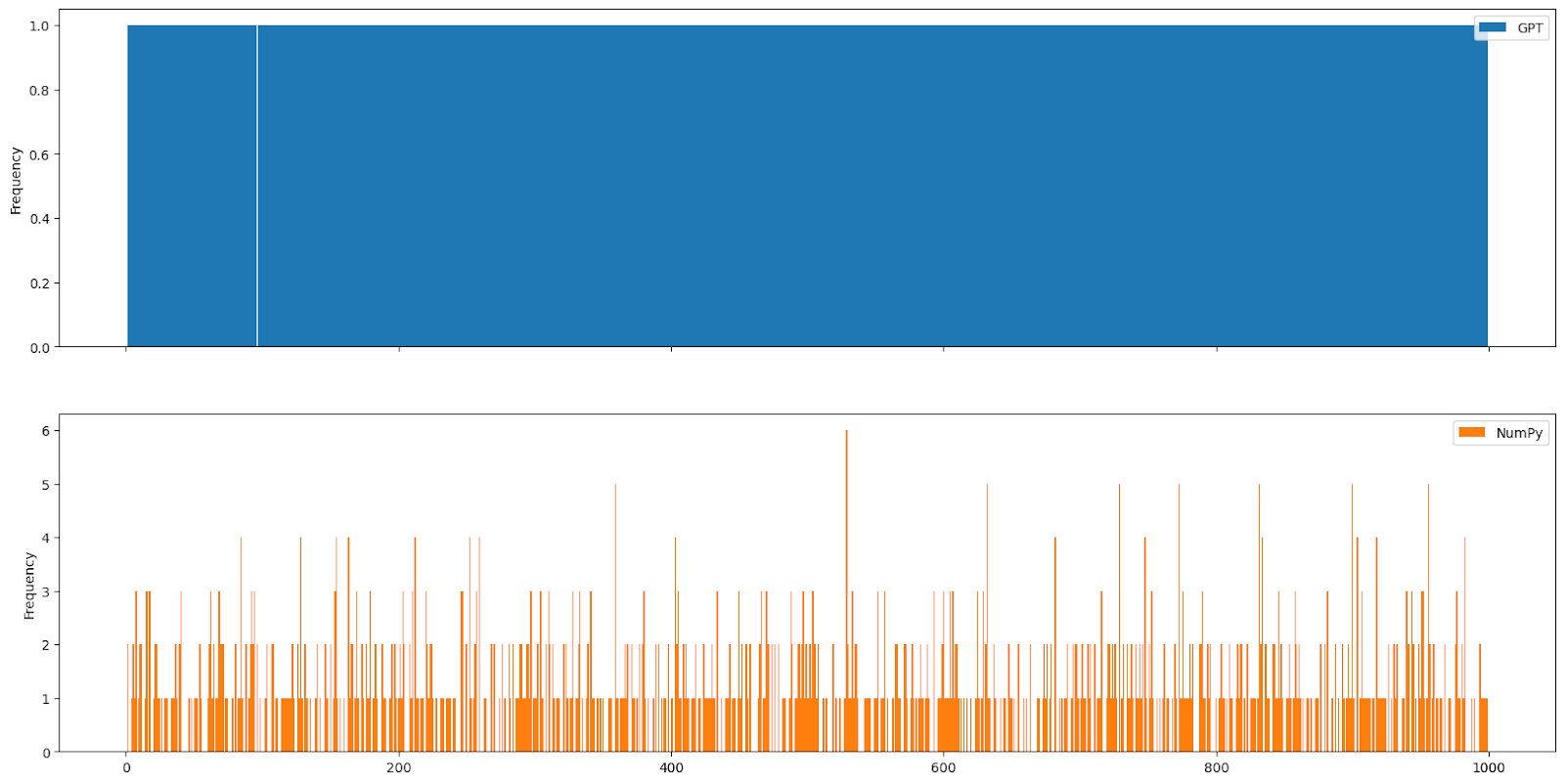
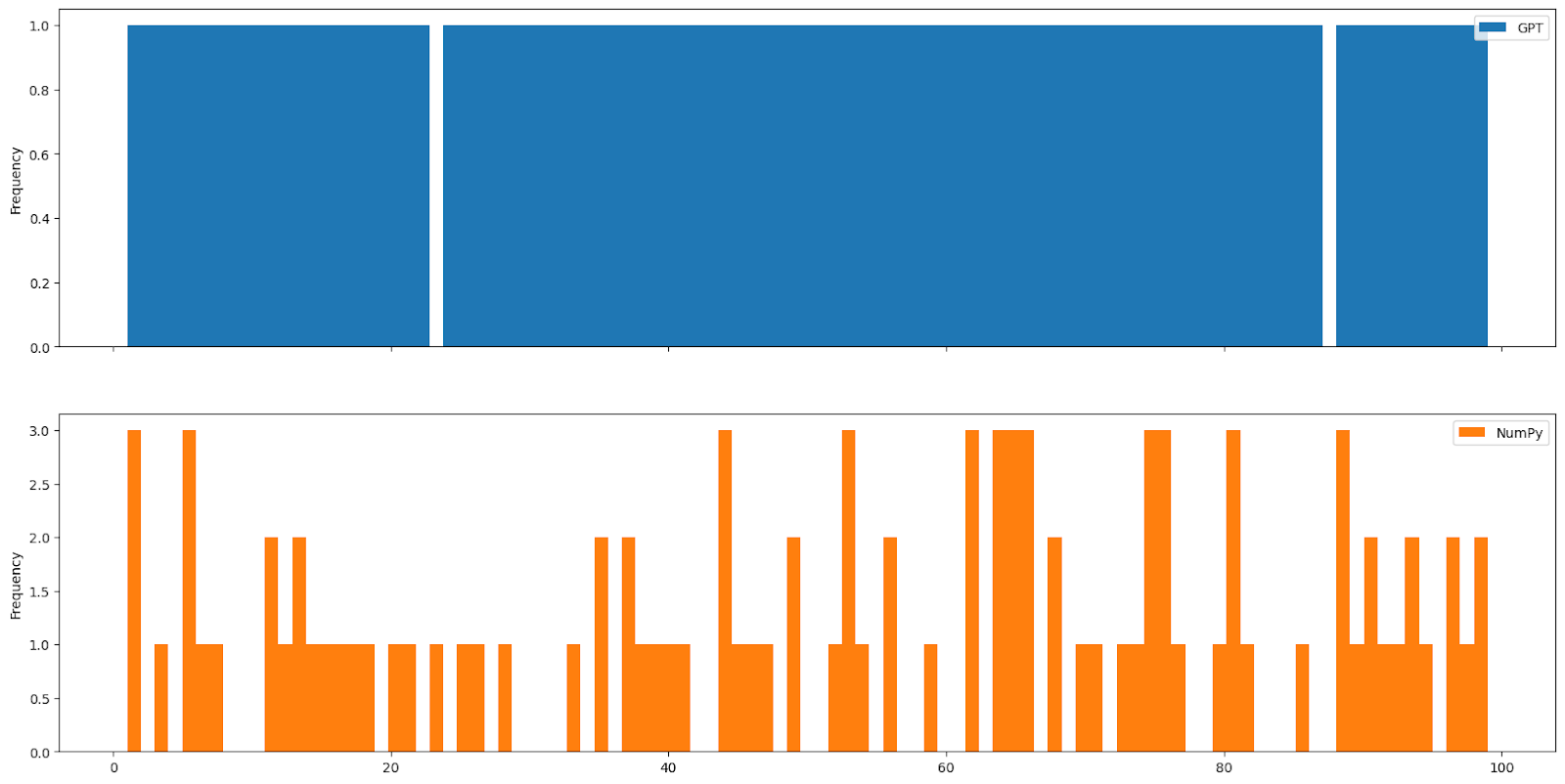

This happened over and over again. Even with the frequency_penalty set to 0, GPT was far less likely to select any given number multiple times than a truly random distribution.
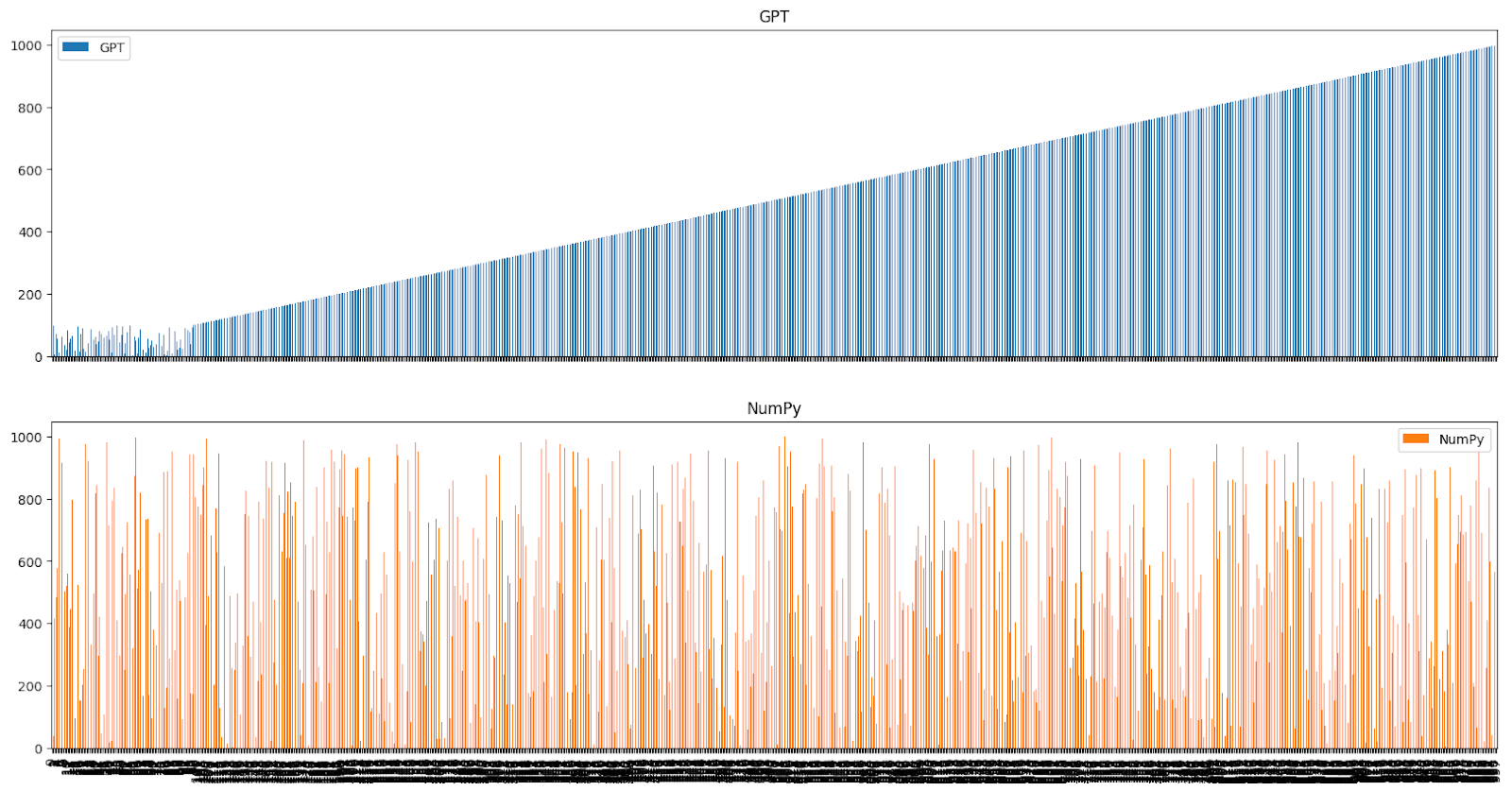
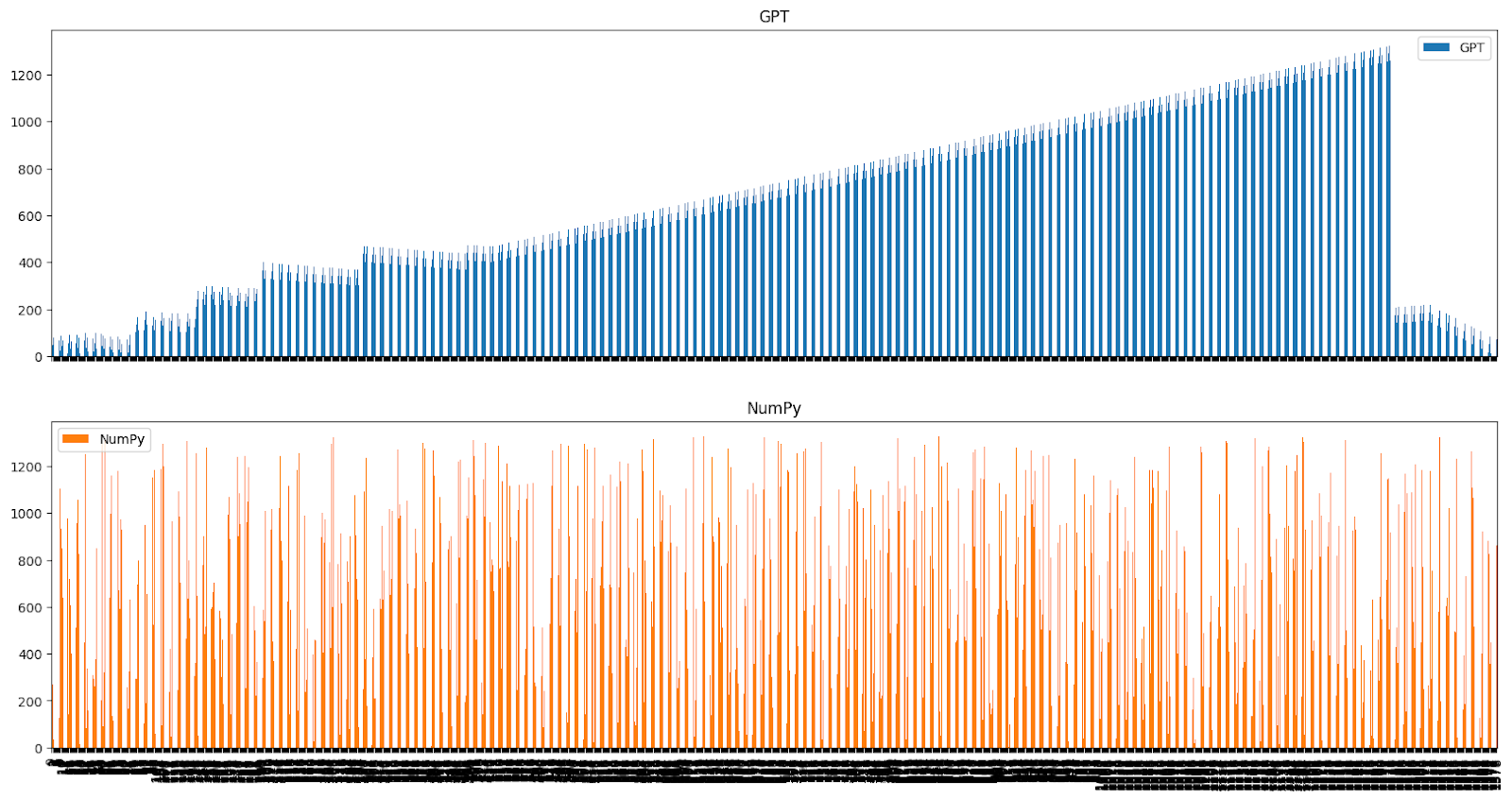
In the 1000 number group, some of those perfectly uniform distributions were sorted or semi-sorted — but sorting never occurred in the 10 or 100 number groups. In 20 samples I saw this three times, here’s the data in the order it was generated with GPT once again in blue and numpy.random.randint in orange.
Once, GPT repeated the same short sequence of numbers about 300 times until it was cut off by the API for running out of tokens. The sequence was 12, 34, 56, 78, 90, 23, 45, 67, 89. It took me a moment to see the not-so-clever pattern:
The first five numbers are the digits 1234567890 split every two digits. The remaining four numbers are the digits 23456789 split the same way.
If you do a Google search for these numbers, you’ll see that a lot of practice homework problems and other simple examples use this really-easy-to-type pattern, or small variations on it, for sample numbers.
So, most likely, GPT learned this lazy behavior from data scraped from the web.
Sometimes, GPT produced something that actually looked pretty random! Like this one (the histogram is on top, and the numbers in the order they were produced on the bottom). Eyeballing it I estimated 7 / 60 attempts had a random-looking distribution like this:

Histogram

Numbers in order
I’m sure there is more to learn from this data, and even more could be discovered with more experimentation and dataset generation. For example, there were several perfectly uniform distributions where I couldn’t readily discern other patterns or a systemic mechanism for producing the numbers.
That brings us to our usual call for you to…
Challenge Yourself!
The code we used to generate datasets is fairly robust and easily modified. And although the code we used to analyze this data is a little crude, it’s good enough to reuse and repurpose. So here are three ways to challenge yourself on a weekend project:
Analyze our datasets and find something we missed.
Generate some more datasets and try to find new patterns.
Switch the model to GPT-4 or another OpenAI model and see if you can find evidence that these problems persist, or change from model to model in some way.
Add some rigor: the most well-established tests for randomness are the diehard tests; running some of these tests on GPT output would bring more rigorous insight into just how random GPT is.
If you do hack something up, let us know. We might feature it in this newsletter!
Remember…
The Lab Report is free and doesn’t even advertise. Our curricula is open source and published under a public domain license for anyone to use for any purpose. We’re also a very small team with no investors.
Help us keep providing these free services by scheduling one of our world class trainings, requesting a custom class for your team, or taking one of our open enrollment classes.
Reply